7 Andmete sisestamine ja lihtsamad päringud
Nüüdseks oleme me tutvunud andmebaasi tabelite lisamisega. Kuidas nendesse tabelitesse aga andmeid lisada?
Selleks on kaks võimalust – üksikute kirjete lisamine ning massandmete sisestamine failist.
Käesolevas peatükis tutvumegi kõigepealt üksikute kirjete sisestamisega ning seejärel proovime lisada massandmeid eelmises peatükis loodud Netflixi andmebaasi.
Üksiku kirje lisamine
Üksiku kirje lisamiseks näeb SQL lause üldkuju välja selline:
INSERT INTO <tabeli nimi> (veerg, veerg2, ... )
VALUES (veeru1_väärtus, veeru2_väärtus, ...);
Siinkohal on oluline märkida, et kui meil on mõni veerg, millele me oleme määranud vaikeväärtuse või mille andmetüübiks on serial, võime me uut kirjet lisades selle veeru väärtuse lisamata jätta.
Olgu meil tabel Inimesed veergudega:
- id
- andmetüüp serial
- primaarvõti
- eesnimi
- andmetüüp varchar (50)
- ei luba tühjasid väärtusi
- perekonnanimi
- andmetüüp varchar (50)
- ei luba tühjasid väärtusi
- sünnipäev
- andmetüüp date
- ei luba tühjasid väärtusi
See tabel on meil varasemas peatükis juba DBeaverisse lisatud. Kui me nüüd soovime lisada tabelisse Inimesed isikut, kelle eesnimi on ‘Oskar’, perekonnanimi ‘Ohakas’ ning sünnipäev ‘2002-06-17’, saaksime me seda teha kahte moodi:
INSERT INTOInimesed (id, eesnimi, perekonnanimi, sünnipäev)
VALUES (1, 'Oskar', 'Ohakas', '2002-06-17')INSERT INTOInimesed (eesnimi, perekonnanimi, sünnipäev)
VALUES ('Oskar', 'Ohakas', '2002-06-17')
Esimesel juhul täpsustame me ise veeru id väärtuse, kuid teisel juhul laseme me andmebaasil ise id väärtuse genereerida, sest veeru id andmetüübiks on serial.
Proovige neid SQL lauseid ka ise SQL konsoolil jooksutada. Mis juhtub?
Illmselt saate te teise SQL lause korral veateate, et id väärtusega 1 on juba kasutusel. See ilmneb seetõttu, et PostgreSQL serial andmetüüp ei tööta päris korrektselt juhul, kui me vahepeal ise selle andmetüübiga veeru väärtust määrame. Nimelt hoiab serial andmetüüp mälus indeksit, mis aitab tal alati ühe võrra suuremat arvu genereerida. Kui aga lisada uus kirje täpsustades ise serial andmetüübiga veeru väärtust, ei uuendata seda mälus hoitavat indeksit. Proovides siis aga hiljem lisada kirjet, mille korral veeru väärtus automaatselt genereeritaks, ilmnebki veateade, et see id on juba kasutuses, sest mälus hoitav indeks on tegelikust suurimast id-st maas. Selle probleemi vältimiseks tuleks võimalusel alati jätta serial andmetüübi väärtus ise täpsustamata.
Et praegu mälus hoitav indeks siiski õigeks muuta, jooksutage SQL konsoolil lauset:
SELECTsetval('inimesed_id_seq', (SELECT MAX (id) FROM Inimesed));
Proovige nüüd uuesti jooksutada SQL lauset isiku Oskar Ohakas lisamiseks, jättes id väärtus täpsustamata. Nüüd peaks see õnnestuma.
Kõiki lisatud kirjeid näete te tabeli Inimesed vahelehe Data all (ilmselt tuleb andmebaasi vaadet enne ka värskendada parem klikates andmebaasil public ja valides seejärel Refresh).

Nagu ülesandest välja tuleb, peab alati veenduma, et veeru väärtused lisatakse samas järjekorras, nagu veerud on SQL lauses kirja pandud. Vastasel juhul satub veeru alla vale väärtus ning teile antakse sellest veateatega märku. Halvimal juhul ei saa te eksituse korral isegi veateadet, sest vahetusse läinud veergude andmetüübid kattusid. Näiteks kui tabelisse Inimesed kirjet lisades vahetada ära eesnime ja perekonnanime väärtused, ei tuleks veateadet, sest tunnuste eesnimi ja perekonnanimi andmetüübid kattuvad.
Massandmete failist lugemine
Vahel on vaja andmete ükshaaval sisestamise asemel lisada neid andmebaasi hulgi. Sellistel juhtudel on vaja andmete failist lugemist.
Proovimegi nüüd lugeda eelmises peatükis loodud Netflixi andmebaasi tabelitesse suure hulga andmeid.
Kõigepealt veendu, et kõik eelmises peatükis kirjeldatud tabelid oleks loodud (Riigid, Teosed, Isikud, Lavastamine, Naitlemine). Seejärel tõmba alla vajalikud andmefailid siit ning paki allatõmmatud kaust lahti.
Kuna failist andmete lugemiseks on DBeaveril vaja ligipääsu teie arvutis olevatele andmefailidele, tuleb see luba DBeaverile anda. Ubuntu kasutajatel peaks vajalikud õigused andmefailidele juba olemas olema ning macOS kasutajatel on andmefailidele ligipääsu andmise protsess lihtne – pärast massandmete lisamise SQL lause jooksutamist avaneb aken, kus te saate ligipääsu failidele lubada. Windowsi operatsioonisüsteemi kasutajad peavad aga DBeaverile ligipääsu andmefaile sisaldava kausta jaoks käsitsi andma. Seega kui sa kasutad Windowsi operatsioonisüsteemi, ava see juhis ning täida kõik sammud.
SQL lause üldkuju, mille abil saab andmeid failist tabelisse lugeda, on järgnev:
COPY <tabeli nimi>
FROM '<täielik tee andmefailini>'
DELIMITER E'\t'
ENCODING 'UTF-8'
CSV;
Tabeli nimi tuleb asenda tabeliga, kuhu soovid andmeid lugeda, näiteks Riigid. Täielik tee andmefailini peaks olema näiteks Windowsis midagi sellist: ‘C:\\Users\\Kasutaja\\Desktop\\Andmed\\riigid.csv’. DELIMITER ehk eesti keeles eraldaja määrab ära, kuidas on .csv failis olevad väärtused omavahel eraldatud. Meie .csv failides on eraldajaks tab ehk siis E’\t’. ENCODING määrab ära faili tekstikodeeringu, milleks meil on ‘UTF-8’. CSV märgib lause lõpus ära, et me soovime andmeid lugeda .csv failist.
Avage nüüd DBeaver ning jooksutage äsja tutvustatud SQL lauset iga tabeli jaoks. Andmefailid on nimetatud samade nimedega, nagu meie Netflixi andmebaasis olevad tabelid, seega tabelile vastavat andmefaili peaks olema üpriski lihtne leida.
Igaks juhuks viime siiski vastavusse meie andmebaasis olevad tabelid ning neile vastavad andmefailid:
- Riigid -> riigid.csv
- Teosed -> teosed.csv
- Isikud -> isikud.csv
- Lavastamine -> lavastamine.csv
- Naitlemine -> naitlemine.csv
Kui iga tabeli jaoks on andmed andmebaasi lisatud, võite avada näiteks tabeli Isikud ning liikuda Data vahelehe alla. Nüüd peaksite te nägema igal real ühe isiku kohta käivaid andmeid. Kui andmeid pole näha ning SQL lauseid jooksutades vigu ei ilmnend, siis proovige andmebaasi vaadet värskendada. Selleks vajutage parem klikk andmebaasi public peal ning avanenud valikutest klikake Refresh peal.
Kuna me lisasime nüüd igasse tabelisse suure hulga andmeid, millel olid veeru id väärtused käsitsi määratud, ilmneb jällegi viga seoses serial andmetüübiga. Selle parandamiseks jooksutage järgnevaid SQL lauseid SQL konsoolis:
SELECTsetval('riigid_id_seq', (SELECT MAX (id) FROM Riigid));SELECT setval('teosed_id_seq', (SELECT MAX (id) FROM Teosed));SELECT setval('isikud_id_seq', (SELECT MAX (id) FROM Isikud));SELECT setval('lavastamine_id_seq', (SELECT MAX (id) FROM Lavastamine));SELECT setval('naitlemine_id_seq', (SELECT MAX (id) FROM Naitlemine));
Päringud
Nüüd, kui meil on andmebaasis hulk andmeid olemas, on õige aeg mõelda sellele, kuidas andmeid andmebaasist pärida. Päringud aitavad meil andmebaasile “küsimusi” esitada, millele andmebaas seejärel vastab. Päringu süntaks näeb välja selline:
SELECT veerg1, veerg2, ..., veergnFROM <tabeli nimi>;
Seega päringus saab täpsustada, mis tabelist ning millistest tabeli veergudest soovime me andmeid saada. Kui on soov näha tabeli kõikide veergude sisu, siis selle asemel, et loetleda ükshaaval ette kõik tabeli veerud, võib kirjutada:
SELECT * FROM <tabeli nimi>;
Siin * tähistabki kõiki tabelis olevaid veerge.
Selleks, et saada parem aimdus, kuidas päringud töötavad ning mida siis ikkagi meile väljastatakse, proovime Netflixi andmebaais ühte lihtsat näidet – pärime andmebaasist kõikide riikide nimed ning rahvastikuarvud.
Selleks ava DBeaveri SQL konsool ning käivita seal järgnev SQL lause:
SELECT nimi, rahvastikuarv FROM Riigid;
Teile peaks tulema nähtavale järgnev sisu:
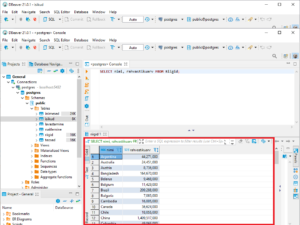
Nagu näha, siis päringu vasteks tulid kõik tabelis Riigid olevad riigid ning nende rahvastikuarvud. Vaata nüüd tabeli Riigid vahelehte Data. Sealt peaks olema nähtav, et tegelikult oli meil tabelis Riigid palju rohkem veerge ning andmeid, kuid päringu abil saime me tabelist valida vaid selle info, mis meile oluline on.
See oli aga äärmiselt lihtne päring. Sellest, kuidas koostada juba keerukamaid päringuid, saab lugeda käesoleva õpiku teisest suurest peatükist “Andmebaaside päringud”.
Selles peatükis Netflixi andmebaasi lisatud andmed on pärit siit ja siit ning need on kohandatud sobivaks Siim Tanel Laisaare poolt.
