58 Andmetega tutvumine ja nende puhastamine
Enne andmete analüüsimist, tuleks andmetest saada ülevaade, sest sageli on töödeldavad andmetabelid väga suured ning nende manuaalne ülevaatamine on liiga ajamahukas. Pandas pakub andmete esmaseks ülevaateks mitmeid võimalusi.
Esimene tegevus, mida andmetabeliga teha, on teada saada kui suur on tabel ehk kui palju on selles ridu ja veerge. Selleks saab kasutada funktsiooni shape, mis tagastab kaheelemendilise enniku, kus esimene element on ridade arv ja teine veergude arv. Loeme kasvuhoonegaaside tabeli veebist, kus on andmed Euroopa riikide gaaside kogusest iga elaniku kohta vahemikus 1990-2018.
import pandas as pd # Andmed url = 'http://kodu.ut.ee/~merka123/plotly/kasvuhoonegaasid.csv' csv = pd.read_csv(url, encoding='UTF-8', sep=';') # Uurime, mitu veergu ja rida on selles tabelis. print(csv.shape)
>>> %Run guido.py (33, 31)
Näeme, et tabelis on 33 rida ja 31 veergu. Järgmisena vaatame andmeid tabelis. Selleks, et mitte tervet tabelit väljastada, saab kasutada funktsioone head, mis tagastab read tabeli algusest, ja tail, mis tagastab read tabeli lõpust. Kuvame tabeli esimesed viis rida ja kümme viimast rida. Mõlemale funktsioonile võib anda argumendiks kuvatavate ridade arv, vaikimisi kuvatakse viis rida.
print(csv.head()) print(csv.tail(10))
>>> %Run guido.py GEO (Codes) GEO (Labels) ... 2017 2018 0 BE Belgium ... 10.8 10.8 1 BG Bulgaria ... 8.8 8.3 2 CZ Czechia ... 12.4 12.2 3 DK Denmark ... 8.9 8.9 4 DE Germany (until 1990 former territory of the FRG) ... 11.2 10.7 [5 rows x 31 columns] GEO (Codes) GEO (Labels) 1990 1991 1992 ... 2014 2015 2016 2017 2018 23 SI Slovenia 9.3 8.7 8.7 ... 8.1 8.2 8.6 8.4 8.5 24 SK Slovakia 13.9 12.1 11.0 ... 7.6 7.7 7.8 8.0 8.0 25 FI Finland 14.5 14.0 13.6 ... 11.1 10.4 10.9 10.4 10.7 26 SE Sweden 8.5 8.4 8.3 ... 5.8 5.7 5.6 5.5 5.4 27 UK United Kingdom 14.1 14.3 13.9 ... 8.7 8.3 7.9 7.7 7.5 28 IS Iceland 15.5 14.5 13.9 ... 16.1 16.6 16.9 17.4 17.5 29 LI Liechtenstein 8.0 8.1 8.0 ... 5.4 5.3 5.0 5.1 4.8 30 NO Norway 12.3 11.7 11.2 ... 10.8 10.8 10.5 10.2 10.1 31 CH Switzerland 8.5 8.7 8.6 ... 6.6 6.5 6.4 6.3 6.1 32 TR Turkey 3.9 4.0 4.0 ... 6.1 6.2 6.4 6.7 6.5 [10 rows x 31 columns]
Näeme, et esimeses veerus on riikide kahetähelised koodid, teises on riikide nimed ja ülejäänud veergudes on kasvuhoonegaaside kogused elaniku kohta aasta järgi.
Kuna loeme andmed tekstifailist, siis on oluline üle vaadata ka veergude andmetüübid. Üldiselt oskab Pandas ise määrata õiged andmetüübid, kuid igaks juhuks tasuks kontrollida. Selleks kasutame funktsiooni dtypes.
print(csv.dtypes)
>>> %Run guido.py GEO (Codes) object GEO (Labels) object 1990 float64 1991 float64 1992 float64 1993 float64 1994 float64 1995 float64 1996 float64 1997 float64 1998 float64 1999 float64 2000 float64 2001 float64 2002 float64 2003 float64 2004 float64 2005 float64 2006 float64 2007 float64 2008 float64 2009 float64 2010 float64 2011 float64 2012 float64 2013 float64 2014 float64 2015 float64 2016 float64 2017 float64 2018 float64 dtype: object
Andmetüübid on õiged. Ühtlasi nägime ka andmetabeli veergude pealkirju.
Järgmisena kontrollime, kas andmetes on puuduvaid või tundmatuid väärtusi. Kasutame isna funktsiooni, mis tagastab tabeli, kus on tõeväärtused, vastavalt, kas väärtus on NaN või mitte.
print(csv.isna())
>>> %Run guido.py GEO (Codes) GEO (Labels) 1990 1991 ... 2015 2016 2017 2018 0 False False False False ... False False False False 1 False False False False ... False False False False 2 False False False False ... False False False False 3 False False False False ... False False False False 4 False False False False ... False False False False 5 False False False False ... False False False False 6 False False False False ... False False False False 7 False False False False ... False False False False ....
Näeme, et tervet tabelit ei väljastata ja manuaalselt üle vaadata, kas mõnes veerus on puuduvaid väärtusi, on tülikas. Selleks, et loendada, kui palju on puuduvaid väärtusi veergudes, saab kasutada sum funktsiooni, mis oskab ka tõeväärtusi liita, kus True on 1 ja False on 0. Kasutame sum funktsiooni koos isna funktsiooniga.
print(csv.isna().sum())
>>> %Run guido.py GEO (Codes) 0 GEO (Labels) 0 1990 0 1991 0 1992 0 1993 0 1994 0 1995 0 1996 0 1997 0 1998 0 1999 0 2000 0 2001 0 2002 0 2003 0 2004 0 2005 0 2006 0 2007 0 2008 0 2009 0 2010 0 2011 0 2012 0 2013 0 2014 0 2015 0 2016 0 2017 0 2018 0 dtype: int64
Näeme, et veergudes ei ole ühtegi puuduvat väärtust, sest kõikide veergude summa on 0.
Järgmisena teeme esmase analüüsi kogu tabelile, kus leiame veergude aritmeetilise keskmise, standardhälbe, maksimaalse ja minimaalse väärtuse, ülemise, alumise ja keskmise kvartiili. Kõik need karakteristikuid kasutatakse andmete iseloomustamiseks. Pandase moodulis on funktsioon describe, mille abil saame kõik eelnevalt nimetatud karakteristikud korraga leida.
print(csv.describe())
>>> %Run guido.py 1990 1991 1992 ... 2016 2017 2018 count 33.000000 33.000000 33.000000 ... 33.000000 33.000000 33.000000 mean 12.427273 12.136364 11.451515 ... 9.209091 9.321212 9.193939 std 5.775123 5.857037 5.416302 ... 3.505742 3.533125 3.541093 min 3.900000 4.000000 4.000000 ... 5.000000 5.100000 4.800000 25% 9.100000 8.700000 8.300000 ... 6.400000 6.700000 6.600000 50% 11.100000 10.700000 9.800000 ... 8.400000 8.400000 8.300000 75% 14.500000 14.500000 13.900000 ... 10.900000 11.000000 10.800000 max 34.400000 35.600000 34.500000 ... 19.800000 20.000000 20.300000 [8 rows x 29 columns]
Näeme, et arvutused tehti ainult nende veergudega, milles on arvud ja lisatud on ka väärtuste loendus iga veeru kohta (count). Järgnevas tabelis on selgitatud väljastatud karakteristikuid.
| Väljund | Karakteristik | Selgitus |
mean |
Aritmeetiline keskmine | Väärtuste summa jagatud nende koguarvuga. |
std |
Standardhälve | Hajuvuskarakteristik, mis näitab tunnuse hajuvust (mida suurem, seda suurem on tunnuse hajuvus keskmisest). |
min |
Minimaalne väärtus | Väikseim väärtus |
25% |
Alumine kvartiil | Väärtus, millest väiksemaid või võrdseid väärtusi on ligikaudu 25%. |
50% |
Keskmine kvartiil ehk mediaan | Väärtus, millest suuremaid ja väiksemaid väärtusi on variatsioonireas ligikaudu võrdselt. |
75% |
Ülemine kvartiil | Väärtus, millest suuremaid või võrdseid väärtusi on ligikaudu 25%. |
max |
Maksimaalne väärtus | Suurim väärtus |
Üldiselt võime näha, et kasvuhoonegaaside kogused on aastate jooksul vähenenud. Selle järelduse iseloomustamiseks teeme joondiagrammi Eesti kasvuhoonegaaside koguste kohta 1990-2018. Joonise tegemiseks kasutame Matplotlibi moodulit.
import pandas as pd import matplotlib.pyplot as plt # Andmed url = 'http://kodu.ut.ee/~merka123/plotly/kasvuhoonegaasid.csv' csv = pd.read_csv(url, encoding='UTF-8', sep=';') # Leiame tabelist Eesti andmetega rea, tagastatakse ühe reaga andmefreim eesti_andmed = csv.loc[csv['GEO (Labels)'] == 'Estonia'] # Eraldame Eesti andmetes ainult arvulised andmed eesti_aastad = eesti_andmed.iloc[:, 2:32] # Valime andmed tabelist, kus on ainult Eesti arvulised andmed eesti_aastad.iloc[0].plot.line() # Joonise kuvamiseks peab kasutama show() Matplotlib moodulist plt.show()
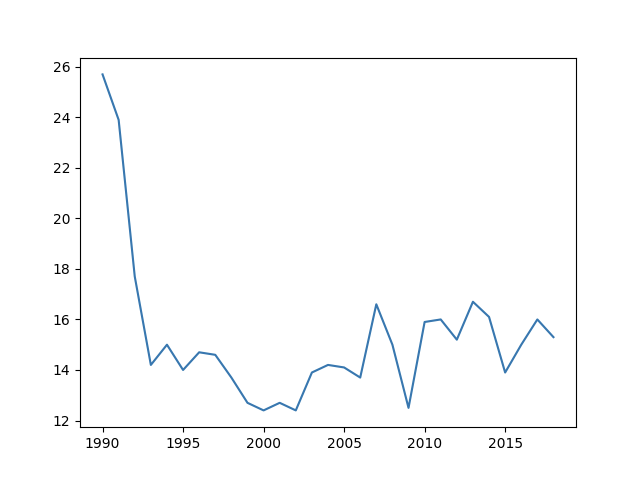
Lisame juurde ka telgedele ja diagrammile pealkirjad, muudame ka joone värvi.
import pandas as pd
import matplotlib.pyplot as plt
# Andmed
url = 'http://kodu.ut.ee/~merka123/plotly/kasvuhoonegaasid.csv'
csv = pd.read_csv(url, encoding='UTF-8', sep=';')
eesti_andmed = csv.loc[csv['GEO (Labels)'] == 'Estonia']
eesti_aastad = eesti_andmed.iloc[:, 2:32]
eesti_aastad.iloc[0].plot.line(xlabel="Aastad",
ylabel="Kasvuhoonegaaside kogus, tonni elaniku kohta",
title="Kasvuhoonegaaside kogused Eestis 1990-2018",
color='#FF7F50')
# Joonise kuvamiseks peab kasutama show() Matplotlib moodulist
plt.show()
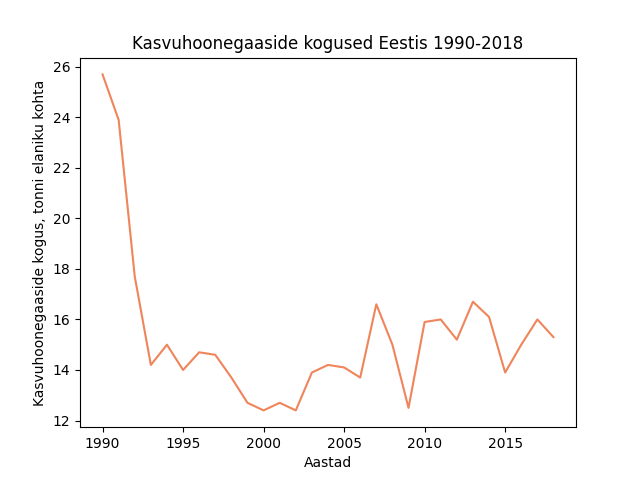
Teeme eelmise andmetabeli põhjal ka kaardi euroopa riikide kasvuhoonegaaside koguste kohta. Selleks kasutame Plotly moodulit.
import pandas as pd
import plotly.express as px
# Andmed
url = 'http://kodu.ut.ee/~merka123/plotly/kasvuhoonegaasid.csv'
csv = pd.read_csv(url, encoding='UTF-8', sep=';')
# locationmode -> riik kaardil ja andmed ühendatakse riigi nime järgi
# location -> veerg, kus saadakse riikide nimed
# color -> andmete veerg
# hover_name -> riikide nimesid kuvatakse hiirega riigile liikumisel
# color_continuous_scale -> värvipaleti määramine
# scope -> kuvatakse ainult Euroopa riike kaardil
# labels -> muudame kuvatavate andmete pealkirju
# title -> kaardi pealkiri
kaart = px.choropleth(csv, locationmode='country names',
locations='GEO (Labels)',
color='2018',
hover_name="GEO (Labels)",
color_continuous_scale=px.colors.sequential.Pinkyl,
scope='europe',
labels={'2018': "Kasvuhoonegaasid, tonni elaniku kohta", 'GEO (Labels)': 'Riik'},
title="Kasvuhoonegaaside emissioon 2018")
kaart.show()
| 🌌 Joonise näide (klõpsa lingil): http://kodu.ut.ee/~merka123/plotly/kasvuhoonegaasid.html |
