101 Piltide klassifitseerimine
Treeningandmete (piltide) leidmine
Selleks, et masin saaks õppida, kuidas üks või teine objekt välja näeb, on tal vaja näidisandmeid. Meie puhul see tähendab, et treenimiseks on vaja koguda pilte. Mida rohkem näidisandmeid on, seda paremini saab masin õppida. Ei ole ühest vastust, kui palju on piisav kogus mingi ülesande jaoks. Me võime siin näite jaoks öelda, et 100 pilti on piisav, et mingisuguseid tulemusi juba saavutada. Aga vahepeal lähevad need kogused miljonitesse. Teisest küljest: mida rohkem on treeningandmeid (pilte), seda rohkem võtab treenimine aega.
Lisaks kogusele on tähtis ka piltide sobivus. Pildid peaks olema üksteisest võimalikult erinevad, et närvivõrk saaks näha erinevaid kujusid ja värve. Soovitatav on võtta pildid, kus on võimalikult vähe häirivaid faktoreid. See aitab vältida olukorda, kus närvivõrk õpib selgeks vale omaduse, mida esineb sageli, kuid ei ole defineeriv pildi juures. Kui näiteks treenida jäneseid tuvastama piltidelt, kus on alati porgand, siis võib närvivõrk õppida tuvastama jänese asemel hoopis porgandit.
Lisainfo: Treeningandmete moonutamine
Samuti tasub proovida enne treenimist treeningandmete moonutamist (venitamine, pööramine, müra lisamine), et tulemuseks oleks töökindlam närvivõrk. See võimaldab saada rohkem kasu samast pildist, sest igat pilti saab mitut eri moodi moonutada.
Andmete jagamine osadeks
Selleks, et närvivõrku treenida ja tulemust kontrollida, on vaja andmed jagada osadeks ja määrata, millistel osadel treenitakse närvivõrku ja millistel osadel kontrollitakse tulemust. Kui seda mitte teha, võib närvivõrk lihtsalt kõik andmed “pähe tuupida”. Kui see juhtub, siis närvivõrk ei omanda üldistavat oskust ja ei õpi tundma andmetes olevaid mustreid. Selline närvivõrk on kasutu kui ta kohtab andmeid, mida ta pole varem pähe tuupinud. Selle “pähe tuupimise” nähtuse nimi on ülesobitamine (overfitting).
Andmete osadeks jagamiseks on mitmeid erinevaid võimalikke lahendusi. Siin tutvustame ühte lihtsaimat, mis eeldab, et andmed jagatakse kaheks osaks: treeningandmestik (training set) ja testandmestik (test set).
Treeningandmestik (training set) koosneb piltidest, mille peal närvivõrk õpib. Treeningandmed moodustavad enamuse kogu näidisandmete hulgast. Neid pilte kasutab närvivõrk selleks, et leida optimaalsed neuronite kaalud.
Testandmestik (test set) koosneb piltidest, mida kasutatakse lõpliku hinnangu andmiseks. Tegu on piltidega, mida närvivõrk pole siiani näinud. Kuna need andmed pole treenimist mõjutanud, siis see aitab simuleerida reaalset olukorda, kus närvivõrk kohtab uusi andmeid. Nende andmete peal arvutatakse ka närvivõrgu lõplik täpsus.
Osade suuruste jaoks puudub alati toimiv lahendus, kuid tihti kasutatakse treening- ja testiandmestiku suhteid nagu 90:10, 80:20 või 70:30. Mida vähem on kogutud andmeid, seda rohkem sõltub tulemus osade suurusest. Lisaks suurustele on tähtis ka sisu. Kui testandmed on liiga erinevad treeningandmetest, siis ei vasta testimistulemused treenimisele.
Lisainfo: Andmegrupid
Põhjalikuma ülevaate andmete gruppidest, kaasa arvatud metoodikatest, kus jagatakse andmeid kolmeks osaks, leiab siit.
Mõtle ja nuputa!
Andmete laadimine PyTorchi
Selles ülesandes kasutame me masinõppekogukonnas populaarset andmekogumit CIFAR-10, mis on mugavalt otse läbi PyTorchi saadav ning ette jagatud treenimis- ja testimisosadeks (läbi train argumendi). Seal olevad pildid on piisavalt kvaliteetsed otseseks kasutamiseks. CIFAR-10 nimi tuleneb sellest, et ta pildid jagunevad kümnesse erinevasse klassi.

Täielikku nimekirja PyTorchi poolt (põhiliselt õppe- ja uuringeesmärkidel) pakutavatest andmekogumitest saab vaadata siit. CIFAR-10 pildid saab kätte (automaatse internetist allalaadimisega) kasutades DataSet-i niiviisi:
from torchvision import datasets, transforms
train_data = datasets.CIFAR10(
root='data', # kaust, kuhu andmed laetakse alla
train=True, # kas soovime treeningandmeid (True) või testimisandmeid (False)
download=True, # kas laeme vajadusel andmed automaatselt alla internetist
transform=transforms.ToTensor() # teisendame pildid tensoriteks
)
test_data = datasets.CIFAR10(
root='data',
train=False,
download=True,
transform=transforms.ToTensor()
)
x, y = next(iter(train_data)) # võtame treenimisandmetest esimese pildi
print(x.shape) # torch.Size([3, 32, 32]) - 3 värvikanalit (RGB), 32x32 pikslit
print(y) # 6 - pildi klass
Lisainfo: Enda piltide laadimine
Juhul kui meil on olemas oma enda pildid, saame kasutada klassi ImageFolder (dokumentatsiooni saab lugeda siit). Sellele klassile tuleb anda kaust, kus on eraldi kaustad iga klassi jaoks, ning igas klassikaustas on antud klassi (y) kuuluvad pildid (x). Selles ülesandes piirdume ainult CIFAR-10-ga.
Kuigi üleval on toodud välja näide, kuidas pilte DataSet-ist ühe kaupa kätte saada, on soovituslik lisaks sellele kasutada PyTorchi poolt pakutavat DataLoader-it, mis võimaldab andmeid laadida suvalises järjekorras ja mitme kaupa (miniplokkides, ingl.k. minibatches), tänu millele muutub treenimisprotsess efektiivsemaks. DataLoader-i kasulikest omadustest saab rohkem lugeda siit.
from torch.utils.data import DataLoader train_loader = DataLoader(train_data, batch_size=16, shuffle=True) test_loader = DataLoader(test_data, batch_size=16, shuffle=True) x, y = next(iter(train_loader)) # võtame miniploki print(x.shape) # torch.Size([16, 3, 32, 32]) - 16 pilti, 3 värvikanalit (RGB), 32x32 pikslit print(y.shape) # torch.Size([16]) - 16 märgendit (klassi, kuhu miniploki pildid kuuluvad)
Mitu pilti korraga ühte miniplokki laetakse on määratud läbi batch_size argumendi; tüüpiliselt on see 32 või 64, siin piirdume 16-ga. Närvivõrgu parameetreid uuendatakse vaid ühe korra iga miniploki lõpus läbi iga pildi ennustuse summeeritud kahju. Argument shuffle=True tähendab seda, et andmeid antakse suvalises järjekorras.

PyTorchi närvivõrgumoodul
Selles peatükis võtame kokku kõik olemasolevad detailid ja hakkame ehitama lihtsat närvivõrgu, mis oskab klassifitseerida CIFAR-10 pilte. Treenimiseks kasutame PyTorchi poolt pakutavat nn.Module klassi, mis lihtsustab närvivõrkude koostamist. Suurem osa koodist jääb samaks, nagu varasemates näidetes.
from torch import nn
class NeuralNetwork(nn.Module): # anname nn.Module-ile nime "NeuralNetwork"
def __init__(self):
super().__init__() # vajalik rida nn.Module-i kasutamiseks!
def forward(self, x):
print(x.shape) # torch.Size([16, 3, 32, 32]) - 16 pilti, 3 värvikanalit (RGB), 32x32 pikslit
Et nn.Module-it kasutada, pole vaja teada klassidest palju. Peamine detail on see, et __init__ meetodis tuleb luua kõik kihid ning forward meetodis tuleb kirjeldada, kuidas andmed neid kihte läbivad.
Deklareerime mooduli kihid pannes kihimuutujate nimede ette self. (tänu sellele saame neid kasutada forward meetodis jälle läbi self parameetri):
def __init__(self):
super().__init__() # vajalik rida nn.Module-i kasutamiseks!
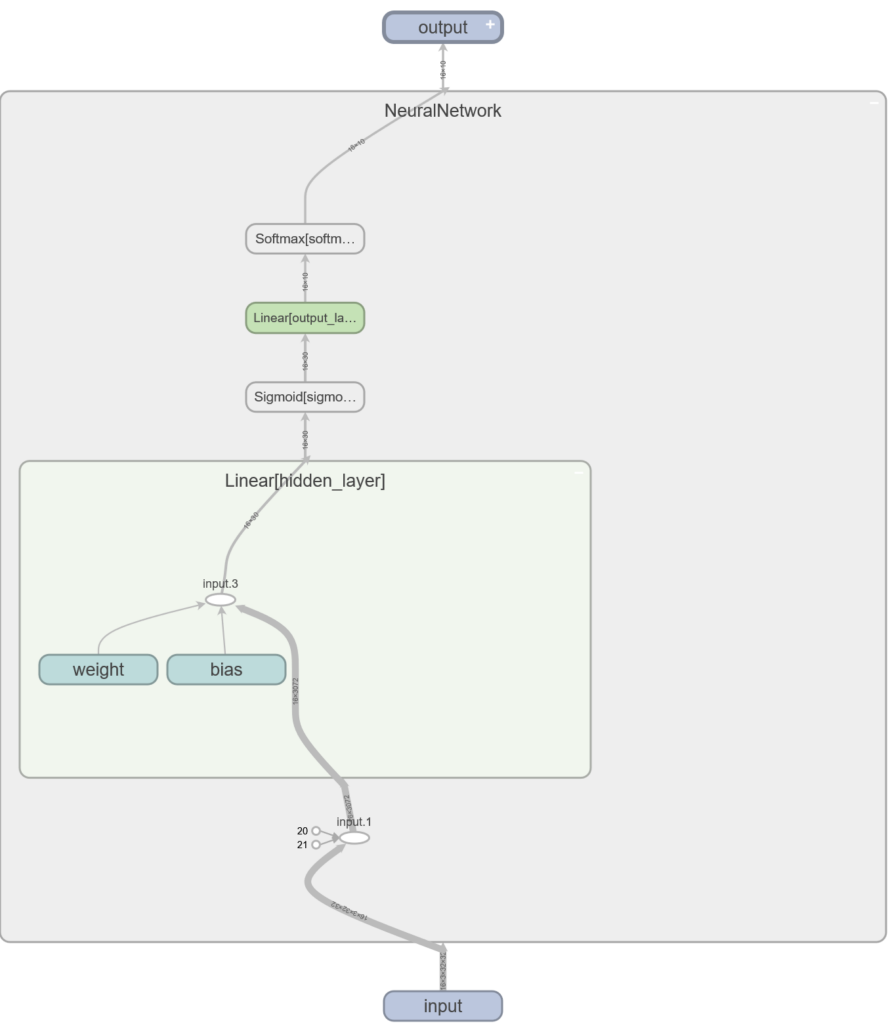
self.hidden_layer = nn.Linear(3 * 32 * 32, 30) # 32x32x3 pikslit, 30 väljundit
self.sigmoid = nn.Sigmoid() # aktivatsioonifunktsioon peidetud kihile
self.output_layer = nn.Linear(30, 10) # 30 sisendit, 10 väljundit (üks iga klassi kohta)
self.softmax = nn.Softmax(dim=1) # aktivatsioonifunktsioon väljundkihile
Viimasel real self.softmax = nn.Softmax(dim=1) määrab argument dim=1 ära, et softmax rakendataks iga pildi kohta eraldi. See on vajalik, kuna me kasutame miniplokke, mille puhul antakse meile x-i 16 pilti korraga. Aktivatsioonifunktsioon nn.Softmax viib väljundkihi neuronid kujule kus nende kogusumma on 1, mis võimaldab neid väärtusi interpreteerida piltide klassi kuuluvuse tõenäosustena (närvivõrgu “ennustuseks” loeme suurima tõenäosusega klassi). Näiteks:
data = torch.tensor([5.5, 3.5, 4.2])
activation_fn = nn.Softmax()
print(activation_fn(data)) # tensor([0.7103, 0.0961, 0.1936]) - 71%, 10%, 19%
Nüüd kui kihimuutujad on deklareeritud, kirjeldame, kuidas andmed neid kihte läbivad iga x-i korral:
def forward(self, x):
x = x.flatten(start_dim=1) # 16x3x32x32 -> 16x3072
z_1 = self.hidden_layer(x) # 16x3072 -> 16x30
a_1 = self.sigmoid(z_1) # 16x30 -> 16x30
z_2 = self.output_layer(a_1) # 16x30 -> 16x10
a_2 = self.softmax(z_2) # 16x10 -> 16x10
return a_2
Esimene x-i transformeeriv rida x = x.flatten(start_dim=1) on vajalik, sest nn.Linear ootab sisendandmeid 1D-kujul, välja arvatud esimene miniplokkide dimensioon (indeks 0), millega tegeleb nn.Linear automaatselt. Argument start_dim=1 tähendab seda, et tensori lamestamisel esimest dimensiooni ignoreeritakse (lamestamist alustatakse indeks 1 dimensiooniga). Nüüd kui x on õigel kujul, läbivad andmed peidetud kihist väljundkihini, kus lõplik tulemus tagastatakse.
Epohhid ja närvivõrgu treenimine
Närvivõrgu treenimisprotsess koosneb epohhitest (epoch). Epohhi jooksul käiakse treeningandmed ühe korra läbi. Treenimine koosneb tavaliselt rohkem kui ühes epohhist. Kui teha liiga palju epohhe, siis tekib ületreenimise oht, sest närvivõrgule antakse piisavalt aega andmetele ülesobituda.
Loome närvivõrgu instantsi, koostame MSE kahjufunktsiooni ja määrame optimeerija õpisammuga 0.1:
net = NeuralNetwork()
loss_fn = nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
Lisainfo: CUDA kasutajatele
Juhul kui oled siiamaani kasutanud CUDA-t, tuleb määrata ka nn.Module-i seadme: net = NeuralNetwork().to(device). Seade rakendub kõikidele kihtidele, mis on deklareeritud antud class NeuralNetwork(nn.Module)-i sees.
Järgmisena hakkame kirjutama tsüklit, mis treenib närvivõrku 10 epohhit:
for epoch in range(10):
for x, y in train_loader: # käime läbi kõik miniplokid
y_hat = net(x) # teeme ennustuse
print(y.shape, y_hat.shape) # torch.Size([16]) torch.Size([16, 10])
optimizer.zero_grad() # nullime eelnevad gradiendid
loss = loss_fn(y_hat, y) # arvutame kahju
# error! y ja y_hat on erineva kujuga, seega ei saa kahju arvutada
Siin tekib probleem! Muutuja y on kujul [2, 5, ..., 1, 5], muutuja y_hat aga kujul [[0.1, 0.2, ..., 0.5], [0.4, 0.1, ..., 0.1], ..., [0.0, 0.7, ..., 0.2]]. Esimeses on tegemist õigete klasside indeksitega, teises aga ennustatud klasside tõenäosustega. Et kahjufunktsioon töötaks, peame muutma y samale kujule nagu y_hat. Näiteks kui y[0] on 2, peaks temast saama vektor [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]. Kuigi saaksime teoorias kirjutada selle probleemi lahendamiseks enda koodi, pakub PyTorch mugavat funktsiooni nn.functional.one_hot, mis teeb terve töö ära meie eest:
for x, y in train_loader: # käime läbi kõik miniplokid
y_hat = net(x) # teeme ennustuse
y = nn.functional.one_hot(y, 10).to(torch.float) # muudame y-i õigele kujule (10 klassi)
optimizer.zero_grad() # nullime kõik varasemad gradiendid
loss = loss_fn(y_hat, y) # arvutame kahju
Nüüd kui kahju on arvutatud, peame me ka arvutama, kuidas see kahju mõjutab iga parameetri (w) väärtust läbi funktsiooni loss.backward(). See funktsioon arvutab gradiendid ja salvestab nad kihtide sisse. Ja lõpuks kasutame optimeerijat, et muuta kaalufaktoreid vastavalt gradiendile.
loss.backward() # leiame, kui palju peame muutma iga kihi parameetrit, et kahju oleks väiksem
optimizer.step() # teeme sammu optimeerija abil (muudame kaale vastavalt gradiendile)
Ning sellega on meie treeningprotsess valmis.

Närvivõrgu testimine
Kui tahame näha, kui hästi meie närvivõrk töötab, siis saame selleks kasutada testimisandmeid. Igas epohhis käime algselt läbi kõik treeningandmed (for x, y in train_loader) ja siis kõik testimisandmed (for x, y in test_loader).
Testimisandmete tsükkel erineb selle poolest, et me ei tee optimeerimist (ei muuda kaale / treeni närvivõrku). Tänu sellele ei saa närvivõrk testiandmed “meelde jätta”: simuleerime reaalse elus olukorda, kus me ei tea, millised andmed meile tulevad. Kui me seda ei teeks, oleks meil võimatu teada kui hästi närvivõrk reaalselt oskab meie probleemi mustreid generaliseerida.
Treenimise vältimiseks jätame ära read loss.backward(), optimizer.zero_grad() ja optimizer.step(). Olenedes statistikatest mis meid huvitavad, võime ära jätta ka lõpliku kahju arvutamise (loss_fn(y_hat, y)).
Lisaks sellele ei pea me ka taustas arvutama gradiente, mida muidu tehakse PyTorchis vaikimisi. Et gradientide arvutamist vältida, peame panema oma koodi with torch.no_grad() konteksti:
for epoch in range(10):
for x, y in train_loader:
... # sama kood, mis varem
with torch.no_grad(): # me ei soovi arvutada gradiente
for x, y in test_loader: # käime läbi kõik miniplokid
y_hat = net(x) # teeme ennustuse
y = nn.functional.one_hot(y, 10).to(torch.float) # muudame y-i õigele kujule (10 klassi)
loss = loss_fn(y_hat, y) # arvutame kahju statistika jaoks
Nüüd on meie treenimiskood palju kiirem, sest me ei arvuta enam mõttetult gradiente.
Järgmine samm on hakata arvutama statistikaid nii treenimis- kui ka testimisandmete peal. Mõlema mõõtmine on tähtis selle jaoks, et märgata ülesobitamist. Ülesobitamise selgeim sümptom on kõrge õigsus (õigete ennustuste protsent; ingl.k. accuracy) treeningandmete peal, kuid tunduvalt madalamatesse õigsus testimisandmete peal. Kui närvivõrk töötab hästi, siis on õigsus kõrge nii treening- kui ka testimisandmetel.
Kuna meie koodis tulevad igas epohhis testimisandmed pärast treeningandmeid, siis epohhi-keskse närvivõrgu õppimise tõttu võib testimisandmete õigsus tulla kõrgem kui treeningandmete õigsus.
Lisainfo: Ülesobitamise põhjused
Ülesobitamist saab tekitada näiteks:
- Liiga suur närvivõrk, mille suur parameetrite arv võimaldab tal treeningandmed meelde jätta; närvivõrgul pole mõtet olla “kokkuhoidlik” ja otsida mustreid.
- Liiga vähe treeningandmeid, mis jällegi teeb pähe tuupimise liiga kergeks. Tegu on sisuliselt sama probleemiga nagu eelmises punktis: närvivõrk on asjatult keeruline treeningandmete koguse suhtes.
- Liiga palju epohhe. Tihtipeale õpib närvivõrk mingiks epohhiks mustrid selgeks, ning edaspidi hakkab ülesobituma. Seetõttu on oluline valida õige epohhide arv.
Närvivõrgu meetrikad
Järgmine samm on hakata arvutama närvivõrgu ennustuste õigsust (õigete ennustuste protsenti). Koostame igas epohhis muutujad train_correct ja train_total, ning test_correct ja test_total. Need muutujad hakkavad hoidma meie õigete ennustuste ja koguennustuste arvu. Koostame ka train_loss_sum ja test_loss_sum muutujad, et arvutada keskmist kahju. Sätime kõigi nelja muutuja algseteks väärtuseks null. Järgmisena käime läbi mõlemad tsüklid ja liidame train_total / test_total muutujatele 1 igas iteratsioonis.
Nüüd kui see on tehtud, peame me leidma, kas mingi ennustus oli õige. Kasutame selleks funktsiooni torch.argmax, mis leiab kõige suurema väärtusega elemendi ja tagastab ta indeksi (ehk klassinumbri). Näiteks torch.tensor([0.1, 0.2, 0.5, 0.2]).argmax() tagastab torch.tensor(2). Kui ennustatud klass on sama, mis tegelik klass, siis suurendame train_correct / test_correct muutujat ühe võrra. Lõpuks arvutame õigsuse ja kahju keskmiseid.
Siin on näidiskood test_loader-i jaoks:
for x, y in test_loader:
y_hat = net(x) # teeme ennustuse
for prediction, correct_class in zip(y_hat, y): # läbime paarikaupa kõik y/y_hat väärtused miniplokis
prediction_class = torch.argmax(prediction) # leiame suurima väärtusega indeksi
if prediction_class == correct_class: # kas ennustus oli õige?
test_correct += 1
test_total += 1
y = nn.functional.one_hot(y, 10).to(torch.float) # muudame y-i õigele kujule kahju arvutamiseks
loss = loss_fn(y_hat, y) # arvutame lõpliku kahju statistika jaoks
test_loss_sum += loss.item() # lisame lõpliku kahju summale
Lisainfo: Rohkem meetrikaid
On olemas väga palju teisi meetrikaid, mida saab kasutada närvivõrgu töö hindamiseks:
- Õigsus (accuracy) kirjeldab kui suur osa andmetest klassifitseeriti õigesti. Olukorras, kus ühte klassi on rohkem kui teisi on tulemus kallutatud selle ühe klassi poole. Võtame näiteks andmestiku kahe klassiga: 99 koera ja 1 kass. Kui närvivõrk alati ennustab, et tegu on koeraga, siis õigsus on 99%, aga ta ei oska tegelikult midagi teha. Kasuta kui klasside osakaal andmetes on võrdne (nii see on nt CIFAR-10 puhul).
- Täpsus (precision) kirjeldab kui suurt osa moodustavad õigesti ennustatud positiivseid (true positive) tulemused kõigist positiivselt ennustatud tulemustest. Kasuta kui tulemuses peab olema väga kindel ja pead vältima valesid positiivseid (false positive) tulemusi.
- Saagis (recall) kirjeldab õigesti ennustatud positiivsete tulemuste osakaalu kõigist tegelikult tõestest tulemustest. Kasuta kui eesmärgiks on klassifitseerida positiivselt võimalikult palju positiivseid tulemusi.
- F1 skoor kombineerib täpsuse (precision) ja saagise (recall), et anda tulemus, mis arvestab mõlemat.
Peale samasuguse koodi kirjutamist ka train_loader-i tsüklisse, saame printida epohhi lõpus statistikat. Selle osa võib vabalt kirjutada nii, kuidas soov on. Siin on näitena toodud f-stringidega formeeritud versioon:
print(f'Epoch {epoch + 1:03} train | avg loss: {train_loss_sum / train_total:.6f}, '
f'accuracy: {train_correct / train_total:.2%}')
print(f' test | avg loss: {test_loss_sum / test_total:.6f}, '
f'accuracy: {test_correct / test_total:.2%}')
Eelneva koodi puhul tuleb väljund selline:
Epoch 001 train | avg loss: 0.005552, accuracy: 20.98%
test | avg loss: 0.005468, accuracy: 25.72%
Epoch 002 train | avg loss: 0.005386, accuracy: 26.99%
test | avg loss: 0.005310, accuracy: 27.91%
...
Epoch 014 train | avg loss: 0.004688, accuracy: 39.11%
test | avg loss: 0.004678, accuracy: 39.73%
Epoch 015 train | avg loss: 0.004663, accuracy: 39.60%
test | avg loss: 0.004659, accuracy: 39.53%
...
Epoch 114 train | avg loss: 0.003915, accuracy: 51.45%
test | avg loss: 0.004193, accuracy: 47.24%
...
Epoch 200 train | avg loss: 0.003642, accuracy: 55.95%
test | avg loss: 0.004221, accuracy: 47.05%
Ning ka esimese 250 epohhi graaf:
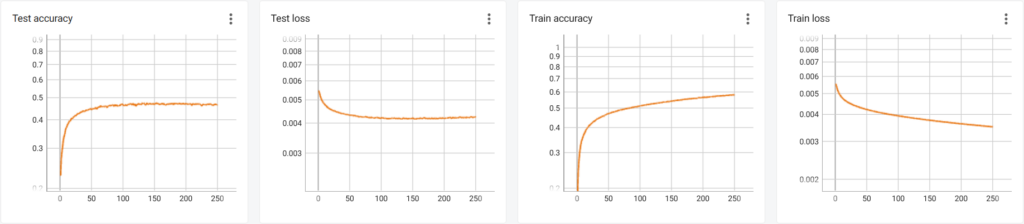
Siin näeme, et mingil hetkel ei suuda meie närvivõrk enam õppida õigesti ennustama rohkem kui 47% piltidest. Treenimistäpsus on aga muutumas aina kõrgemaks, mis võib mõnel hetkel põhjustada isegi märgatavat testimistäpsuste langust.
Lisainfo: Närvivõrgu täiustamine
Inimesed suudavad ennustada õigesti 94% CIFAR-10 klassidest. Parimad närvivõrgud, mis kasutavad palju suuremaid andmekogumeid (transfer learning, loe rohkem siit) ja sadu miljoneid parameetreid, suudavad õigesti ennustada üle 99% CIFAR-10 klassidest. Ühe miljoni parameetriga närvivõrgud suudavad ennustada üle 96%. Isegi koduarvutis treenitavatel närvivõrkudel, millele antakse vaid CIFAR-10 treeningandmeid, on võimalik saavutada üle 80% õigsuse.
Soovi korral võib üritada teha paremaks meie olemasolevat närvivõrku läbi meetodite, mida siin peatükis ei käsitleta. Selleks võib proovida:
- Tuunida hüperparameetreid: mis juhtub, kui valime suurema või väiksema õpisammu
lr, epohhite arvu või miniplokkide suurusebatch_size? - Kasutada keerulisemaid kahjufunktsioone: mis juhtub, kui asendada MSE cross-entropy-ga (loe rohkem siit)?
- Kasutada keerulisemaid optimisatsioonialgoritme: mis juhtub, kui võtta kasutusse SGD-d momentumi ja L2 regularisatsiooniga või Adam?
- Muuta närvivõrgu kihte: mis juhtub, kui lisame teise peidetud
nn.Linearkihi, koostame konvolutsioonilised kihid, muudame aktivatsioonifunktsioone või lisame olemasolevale rohkem neuroneid? - Moonutada pilte: mis juhtub, kui muudame juhuslikult kontrasti, suurust või värve?
Tihtipeale kasutatakse optimaalsete hüperparameetrite leidmiseks algoritme (nt grid search), mis proovivad ise läbi erinevaid väärtuste kombinatsioone, et leida parim. Nende kasutamine on aga keerukas ja aeganõudev. Rohkem saab lugeda siit.
Mõtle ja nuputa!
Lisalugemist
- “Neural networks”, 3Blues1Brown — https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi
- “Tehisintellekti algkursus”, Tartu Ülikool — https://courses.cs.ut.ee/2020/Tehisintellekti_algkursus
- “Neural Networks and Deep Learning”, Michael Nielsen — http://neuralnetworksanddeeplearning.com
- “Learn the Basics”, PyTorch — https://pytorch.org/tutorials/beginner/basics/intro.html ja https://www.youtube.com/playlist?list=PL_lsbAsL_o2CTlGHgMxNrKhzP97BaG9ZN
- “CS231n: Convolutional Neural Networks for Visual Recognition”, Stanford University — https://www.youtube.com/playlist?list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk
- “Dive into Deep Learning” — https://d2l.ai ja https://d2l.ai/d2l-en.pdf
