100 Praktiline näide pildi klassifitseerimise kohta
Kasutame näite jaoks Pythoni pakki fast.ai, mis teeb PyTorch kasutamise arendajale mugavamaks. Kogu näite võib proovida käima panna oma arvutis. Aga see eeldab, et vajalikud pakid on vaja installida. PyTorch ise võtab vähemalt 3 GB kettaruumi. Osade näidete jooksutamine vajab arvutis head graafikakaarti või siis palju aega. Võimalus on näiteid jooksutada näiteks Google Colab keskkonas.
Aastal 2015 ilmus XKCD keskkonnas järgmine pilt:

Vaatame siin peatükis, kuidas tuvastada loomi vaid mõne minutiga. Ning selle tegemiseks ei ole vaja väga põhjalikke eelteadmisi ega väga nõudlikku arvutit.
Teeme läbi näite, kuidas eristada kasse ja koeri. Sammud on järgmised:
- Kasutame DuckDuckGo pildiotsingut, et leida kasside pilte
- Kasutame DuckDuckGo pildiotsingut, et leida koerte pilte
- Kasutame eeltreenitud mudelit, et õpetada seda eristama kasse ja koeri
- Jooksutame saadud mudelit, et kontrollida, kas ta klassifitseerib pilte õigesti
Keskkonna seadistus
Vajalikud teegid:
Kui jooksutada koodi näiteks Google Colab keskkonnas, siis piisab seal järgmisest reast:
!pip install -Uqq fastai duckduckgo_search
Loome abifunktsiooni, millega pilte otsida:
from duckduckgo_search import ddg_images
from fastcore.all import *
def search_images(term, max_images=30):
print(f"Searching for '{term}', count: {max_images}")
return L(ddg_images(term, max_results=max_images)).itemgot('image')
Loodud search_images funktsiooni otsib etteantud otsingutekstiga pilte vastavalt soovitud kogusele. Kui kogust ei määrata, otsitakse 30 pilti. Funktsiooni sees ddg_images otsib pildid ja tagastab saadud tulemused järjendina (list), kus iga element on sõnastik (dictionary). L klass on osa fastcode pakist, mis võimaldab mugavalt listist filtreerida välja vaid teatud võtmega väärtused. Ehk siis kuna iga pildi kohta tagastatakse pildi veebiaadress, pealkiri, kõrgus, laius jne, aga meid huvitab vaid veebiaadress, siis itemgot meetodiga saab listi vaid image võtmete väärtustest.
Piltide (andmete) otsimine
Kasutame eelnevalt loodud funktsiooni, et otsida kasside ja koerte pilte. Näiteks otsime ühe kassi pildi (otsinguks kasutame “cat photos”):
urls = search_images('cat photos', max_images=1)
urls[0]
Kui eelnev kood käima panna Jupyteris, peaksime nägema ühe pildi linki. Võime selle brauseris avada ja veenduda, kas tegemist on kassiga. Kui jooksutad mõnes IDE-s, pead aadressi nägemiseks selle välja printima (print(url[0])).
Mugavam oleks aga neid pilte kohta näha. Kirjutame selleks järgmise koodi:
from fastdownload import download_url dest = 'cat.jpg' download_url(urls[0], dest, show_progress=False) from fastai.vision.all import * im = Image.open(dest) im.to_thumb(256, 256)
Kood tõmbab eelnevalt leitud ühe pildi (url[0]) alla faili "cat.jpg". Seejärel loetakse antud failist pildiobjekt ja kuvatakse selle väike versioon ehk kuvatõmmis (thumbnail, maksimaalselt 256 pikslit kõrge või lai).
Selle koodi käivitamisel Jupyteris peaks näitama ühe kassi pilti. Kui jooksutad koodis IDE-s, pead lõppu lisama veel show() väljakutse: im.to_thumb(256, 256).show().
Toimime samamoodi ühe koera pildi saamiseks:
download_url(search_images('dog photos', max_images=1)[0], 'dog.jpg', show_progress=False)
Image.open('dog.jpg').to_thumb(256,256)
Kood on tegelikult sama. Oleme seda lihtsalt lühendanud kahe rea peale.
Treenimiseks on meil aga vaja rohkem pilte. Kirjutame selle järgmise koodi:
searches = ('cat', 'dog')
# create a new parent folder
path = Path('cat_or_dog')
from time import sleep
for search in searches:
# create a subfolder for current search term
dest = (path/search)
dest.mkdir(exist_ok=True, parents=True)
# download images
download_images(dest, urls=search_images(f'{search} photo'))
sleep(10) # Pause between searches to avoid over-loading server
# try some other searches too - sitting animalt
download_images(dest, urls=search_images(f'{search} sitting photo'))
sleep(10)
# let's also try walking animals
download_images(dest, urls=search_images(f'{search} walking photo'))
sleep(10)
# let's resize all the images
resize_images(path/search, max_size=400, dest=path/search)
Vaatame, mida eelnev kood teeb. Alguses defineerime ära enniku erinevate loomadega (need on need, keda me tahame piltidelt tuvastama hakata). Seejärel määrame eraldi kausta, kus hakkame otsitud pilte hoidma. time moodulist kasutame sleep funktsiooni selleks, et otsingute vahel väike paus teha (et me ei koormaks otsingumootorit üle, mis võib põhjustada ühenduse piiramise).
Käime läbi kõik klassid, mida me algselt määrasime (meie näites kass ja koer). Määrame ära sihtkausta, kuhu tõmmatakse looma pildid. Näiteks kasside puhul cat_or_dog/cat. Edasi tõmbame alla pilte vastavalt määratud otsingutekstile. Selleks, et suudaksime looma tuvastada võimalikult erinvates tegevustes/poosides, otsime kõigepealt lihtsalt looma pilte, seejärel istuva looma pilte ja lõpuks kõndiva looma pilte. Siia võib vabalat veel lisada otsingutekste, et leida võimalikult erinevaid loomapilte. Kõik need pildid tõmmatakse määratud looma kausta. Lõpuks käivitatakse piltide suuruse muutmise funktsiooni, mis käib kõik allatõmmatud pildid läbi ja muudab nad vajadusel väiksemaks (nii, et pikima külje pikkus oleks maksimaalselt 400 pikslit).
Mudeli treenimine
Kuna mõned allatõmmatud pildid ei pruugi olla korrektsed (vigased pildifailid jms), siis eemaldame sellised:
failed = verify_images(get_image_files(path)) failed.map(Path.unlink)
Mudeli treenimiseks peame andmed sobivale kujule viima. Selleks loome DataLoaders objekti. See sisaldab treeningandmeid (training set, neid pilte kasutatakse mudeli loomiseks) ja valideerimisandmeid (validation set, nende piltidega kontrollitakse mudeli täpsust ja vajadusel tehakse mudalisse täiendusi – treenimisel neid pilte ei kasutata). fastai pakis on selle jaoks olemas abiklass DataBlock.
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=[Resize(192, method='squish')]
).dataloaders(path, bs=32)
dls.show_batch(max_n=6)
Vaatame, mida DataBlock konstruktori argumendid tähendavad:
blocks=(ImageBlock, CategoryBlock)– meie mudeli sisendiks on pildid ja väljundiks on kategooria (kass või koer).get_items=get_image_files– sisendi saamiseks kasutatakseget_image_filesfunktsiooni, mis leiab pildifailid kaustast.splitter=RandomSplitter(valid_pct=0.2, seed=42)– sisendandmed jagatakse juhuslikult treening- ja valideerimisandmeteks, kusjuures valideerimiseks jääb 20% sisenditest (piltidest).get_y=parent_label– märgend (kas kass või koer) iga sisendi (pildi) kohta saadakse kasuta nimest.item_tfms=[Resize(192, method='squish')]– kõik pildid tehakse väiksemaks nii, et need mahuks 192 x 192 piksli sisse ära kasutades vähendamiseks meetodit “squish” (pilt venitatakse vajadusel ruudukujuliseks). Võimalik on ka meetod “crop”, aga selle puhul võib mõni oluline osa pildilt välja jääda (näiteks laia pildi puhul jääb looma sama vähendatud pildilt välja).
Selle koodi tulemusena peaks Jupyteris nägema 6 pilti koos kategooriaga (kass või koer). Kuna need 6 pilti valitakse juhuslikult, võivad kõik olla näiteks kassid. Võib proovida mängida max_n väärtusega, et näha rohkem/vähem pilte.
Loodud dls muutujat saame nüüd kasutada mudeli treenimiseks:
learn = vision_learner(dls, resnet18, metrics=error_rate) learn.fine_tune(3)
Kasutame treenimiseks eeltreenitud mudelit resnet18. Täpsemalt saab eeltreenitud mudelite kohta lugeda siit: https://pytorch.org/vision/main/models.html. Valitud resnet18 on piisavalt kiire ja täpne sellist tüüpi klassifitseerimisülesande jaoks.
fine_tune meetod oskab ära kasutada parimad praktikaid tulemuste parandamiseks.
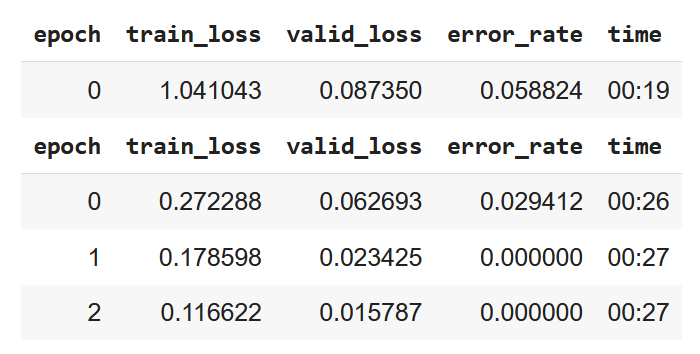
Kui see kood käima panna, peaks nägema treenimise tulemusi. Näiteks:
Kontrollime mudelit
Proovime treenitud mudeliga ennustada mõne pildi klassi. Näiteks proovime järgmist koodi:
download_url(search_images('cat 2022 photos', max_images=1)[0], 'cat1.jpg', show_progress=False)
category, _, probs = learn.predict(PILImage.create('cat1.jpg'))
print(f"This is a: {category}.")
print(f"Probability it's a cat: {probs[0]:.4f}")
Image.open('cat1.jpg').to_thumb(256, 256)
Eelneva koodi puhul oleme kasutanud erinevat otsinguteksti (“cat 2022 photos”). Vastasel korral leiaksime täpselt samad pildid, mida treenimisel kasutati. Testimiseks tuleks kasutada andmeid, mida treenimisel ei ole kasutatud. Eelneva koodi tulemusena peaks kassi tuvastamise täpsus olema 100%-lähedane. Ühtlasi peaks koodi tulemusena välja kuvatama kass pilt, mida tuvastati. probs muutujasse pannakse tõenäosus iga kategooria kohta. probs[0] viitab esimese kategooria peale (kassid), kuna see oli meie eelnevas koodis eespool.
Proovi sama teha koera pildiga. Näiteks selline pilt:

Viiteid
- https://course.fast.ai/ – Tasuta kursus närvivõrkudega õppimise jaoks. Ka siinne näide on paljuski selle peale üles ehitatud.
- https://playground.tensorflow.org/ – Siin saab visuaalselt jälgida, kuidas närvivõrk võiks toimida erinevate ülesannete puhul.
