99 Pildi kategoriseerimine masinõppega – protsessi ülevaade
Pildi kategoriseerimine masinõppega
Ülesanne, mida lahendama hakkame, on kategoriseerimine. Anname arvutile ette ühe pildi ning arvuti annab vastuseks kategooria, millesse see pilt kuulub. Kategooria all mõeldakse siis seda, milline objekt (või objektid) on pildil. Kui näiteks pildil on loom, annab arvuti teada, et see kuulub “looma” kategooriasse. Kui pildil on inimene, siis “inimene” kategooriasse jne. Vaatame siin peatükis, millised on sammud, mida sellise kategoriseerija tegemise jaoks on vaja läbi teha.
Treeningandmete (piltide) leidmine
Selleks, et masin saaks õppida, kuidas üks või teine objekt välja näeb, on tal vaja näidisandmeid õppimiseks. See tähendab, et treenimiseks on vaja koguda pilte. Mida rohkem näidisandmeid on, seda paremini saab masin õppida. Ei ole ühest vastust, kui palju on piisav kogus mingi ülesande jaoks. Me võime siin näite jaoks öelda, et 100 pilti on piisav, et mingisuguseid tulemusi juba saavutada. Aga üldselt lähevad need kogused miljonitesse. Teisest küljest – mida rohkem on treeningandmeid (pilte), seda rohkem võtab treenimine aega.
Lisaks kogusele on tähtis ka piltide sobivus. Pildid peaks olema üksteisest võimalikult erinevad, et närvivõrk saaks näha erinevaid kujusid ja värve. Soovitatav on võtta pildid, kus on võimalikult vähe häirivaid faktoreid. See aitab vältida olukorda, kus närvivõrk õpib selgeks vale omaduse, mida esineb sageli, kuid ei ole defineeriv pildi juures. (Kui näiteks treenida jäneseid tuvastama piltidelt, kus on alati porgand, siis võib närvivõrk õppida hoopis porgandit tuvastama kui jänest).
Samuti tasub proovida treeningandmete moonutamist (venitamine, pööramine, müra lisamine)
enne treenimist, et tulemuseks oleks töökindlam närvivõrk.
See võimaldab saada rohkem kasu samast pildist, sest sama pilti saab mitut eri moodi moonutada.
Täpsemalt saab lugeda ja näiteid vaadata
siit.
Mudeli koostamine
Mudeli all peame siin kohal silmas närvivõrku ja selle struktuuri. Närvivõrgu struktuur on disainitud ja defineeritud programmeerija poolt enne treenimist. See sisaldab endas informatsiooni selle kohta, palju neuroneid närvivõrgus on ja kuidas need omavahel ühendatud on. Piisava suurusega närvivõrk on alati võimeline õppima klassifitseerima, aga sobiv struktuur kiirendab õppimist.
Siin ülesandes on soovitatav kasutada järjestikkust (PyTorch/Keras: Sequential) mudelit. See tähendab, et pilt kui sisendandmed läheb ükshaaval läbi kihtide. Iga kihi väljund on järgneva kihi sisend. Viimase kihi väljundiks on iga pildi kategooriasse kuuluvuse tõenäosus.
Esimeste kihtide ülesanne on tuvastada osalisi omadusi nagu näiteks silm/nina/suu. Selle jaoks on parim kasutada konvolutsioonilisi (convolutional) kihte. Tegu on kihtidega, mis võtavad arvesse vaid lokaalseid väärtuseid korraga. Teisisõnu, konvolutsioonilised kihid õpivad mustreid kõrvutiste andmete (nt pikslite) vahel, mis on täpselt mida me soovime visuaalandmete puhul. Närvivõrgul ei ole tavaliselt optimaalne otsida mustreid kahes pildi eriotstes asetsevate pikslite vahel.
Järgmisena on soovitatav kasutada kihte (ehk aktivatsioonifunktsioone), mis hindavad omaduste tähtsust ja vähendavad lineaarsust (ehk võimaldavad närvivõrgul õppida raskemaid mustreid). Selleks sobivad näiteks ReLU, tanh või sigmoid kihid.
Järgmisena on soovitatav kasutada ahenduskihte (pooling), mis võimaldavad tuvastada objekti hoolimata selle asukohast pildil. Saab öelda, et tegu on kihtidega, mis madaldavad andmete resolutsiooni, lüües mitme lokaalse neuroni väärtused kokku. Kuna nende väljundid on väiksemad nende sisenditest, kiirendavad need kihid ka edaspidiseid arvutusi. Seesuguseid kihte on olemas mitut liiki: näiteks max pooling, average pooling ja sum pooling kihid.
Järgmisena tasub lihtsustada kihi struktuuri, selle jaoks on olemas flattening kiht, mis muudab kihi kuju lihtsamini hallatavaks järgnevate kihtide jaoks (nt 2D -> 1D). Seejärel tuleb kõik tuvastatud omadused omavahel kombineerida, et jõuda objekti klassi
kohta järeldusele. Selle jaoks on täielikult ühendatud kiht (dense ehk fully connected layer), mis ühendab kõikide omaduste väärtused.
Põhjalikuma ülevaate kihtide ja nende omaduste kohta leiab siit.
Treeningandmete osadeks jagamine
Nüüd on olemas närvivõrk mida treenida, kui ka piisavalt pilte, mille peal treenida. Selleks, et treenida ja tulemust kontrollida, on vaja andmed jagada osadeks, et määrata, millistel osadel treenitakse närvivõrku ja millistel osadel kontrollitakse tulemust.
Andmete osadeks jagamiseks on mitmeid erinevaid võimalikke lahendusi.
Siin tutvustame ühte lihtsamatest lahendustest, mis eeldab, et andmed jagatakse kolmeks osaks:
treeningandmestik (training set), valideerimisandmestik (validation set), testandmestik (test set).
Treeningandmestik (training set) andmed on pildid, mille peal närvivõrk õpib. Treeningandmed moodustavad enamuse kogu hulgast. Neid pilte kasutab närvivõrk selleks, et leida närvivõrgu neuronite kaalud.
Valideerimisandmestik (validation set) koosneb piltidest, mida kasutatakse treenimise vahepeal. Valideerimisandmeid on tunduvalt vähem treeningandmetest. Neid pilte kasutatakse selleks, et korrigeerida mudeli parameetreid. Näiteks kasutatakse seda hulka, et leida parim neuronite arv kihis. Samuti aitab see hulk vältida ületreenimist.
Testandmestik (test set) koosneb on piltidest, mida kasutatakse lõpliku hinnangu andmiseks. Tegu on piltidega, mida närvivõrk pole siiani näinud. Kuna need andmed pole treenimist mõjutanud, siis see aitab simuleerida reaalset olukorda. Nende andmete peal arvutatakse ka närvivõrgu lõplik täpsus.
Põhjalikuma ülevaate treeningandmete gruppidest leiab
siit.
Osade suuruste jaoks puudub alati toimiv lahendus, kuid osad võimalikud osakaalud on näiteks (treening-, valideerimis-, testiandmestiku suhted):
- 0.8 : 0.1 : 0.1
- 0.7 : 0.15 : 0.15
- 0.6 : 0.2 : 0.2
Mida vähem on kogutud andmeid, seda rohkem sõltub tulemus osade suurusest. Lisaks suurustele on tähtis ka sisu. Kui valideerimise või testandmed on väga palju erinevad treeningandmetest, siis ei vasta testimise tulemused treenimisele.
Mudeli treenimine
Mudeli treenimine koosneb epohhitest (inglise keeles epoch). Epohhi jooksul käiakse treeningandmed ühe korra läbi. Treenimine koosneb tavaliselt rohkem kui ühes epohhist.
Kui teha liiga palju epohhe, siis tekib taaskord ületreenimise oht, sest närvivõrgule antakse piisavalt aega “treeningandmed pähe tuupida”. Üks lihtsamaid meetodeid on elbow method.
Tehes graafiku loss väärtusest epohhi kohta.
Antud graafikult otsitakse nurga koht ja vastav epohhite arv.
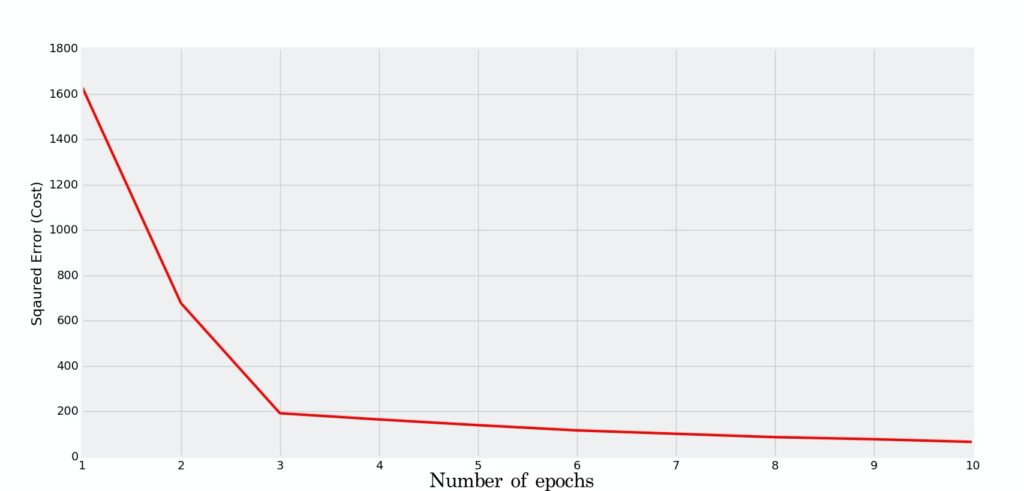
Epohhid jagatakse plokkideks (inglise keeles batch).
Plokk on alamosa treeningandmetest, mille peal parasjagu töötatakse, et kõik andmed ei peaks korraga läbi töötama.
Mida väiksem on ploki suurus, seda kaootilisem on õppimine. Aga mida suurem, seda rohkem mälu kasutatakse.
Batch on tihedalt seotud iterations arvuga.
See arv defineerib, mitu korda andmed üle käiakse.
Korrutades batch_size ja iterations arvu, saab teada mitut pilti närvivõrgule näidatakse.
Sedasi võib juhtuda, et sama pilti kasutatakse ka mitu korda.
Mudeli testimine
Mudeli testimiseks kasutatakse varasemalt kõrvale pandud testimisandmeid.
Testimise eesmärk on teada saada, kuidas tehtud muudatused mudeli toimimist mõjutavad.
Sellele viidatakse osades materjalides ka kui Evaluate.
Mudeli kvaliteeti saab hinnata erinevate parameetrite alusel.
Sõltuvalt kasutatavast teegist võib erineda, millised omadused selle protsessi käigus arvutatakse.
Accuracy kirjeldab kui suur osa andmetest klassifitseeriti õigesti.
See arvutatakse jagades õigesti klassifitseeritud piltide hulka kõigi piltide hulgaga.
Seda on soovitatav kasutada siis, kui klasside osakaal andmetes on võrdne.
Olukorras, kus ühte klassi on rohkem kui teisi on tulemus kallutatud selle ühe klassi poole.
Võtame näiteks olukorra, kus on 99 inimest ja 1 terminaator. Kui sa alati ennustad, et tegu on inimesega, siis see parameeter annab 99% täpsuse, aga lugu lõppeb inimeste jaoks kehvasti, sest terminaator jääb tuvastamata.
Precision kirjeldab kui suur osa moodustavad õigesti ennustatud positiivseid tulemused
kõigist positiivselt ennustatud tulemustest.
Seda on soovitatav kasutada, siis kui tulemuses peab olema väga kindel ja aitab vältida
valesid positiivseid tulemusi.
Näiteks on väga ebaviisakas nimetada inimest terminaatoriks kui ta tegelikult ei ole.
Seega peab antud ennustuses olema kindel.
Recall kirjeldab õigesti ennustatud positiivsete tulemuste osakaalu kõigist tegelikult
tõestest tulemustest.
Seda on soovitatav kasutada, siis kui eesmärgiks on klassifitseerida positiivselt võimalikult
palju positiivseid tulemusi.
Näiteks kui eesmärk on tabada võimalikult palju inimesi ja paar üksikut terminaatorit
või looma, kes sinna hulka satuvad ei ole nii olulised.
F1 Score kombineerib precision’i ja recall’i, et anda tulemus, mis arvestab mõlemat.
Seda on soovitatav kasutada, siis kui mõlemad nii precision kui ka recall on tähtsad.
Seda lahendust on võimalik täiendada andes mõlemale komponendile kaal kui nende tähtsused ei ole võrdsed.
Näiteks kui mudel ei suuda tuvastada väikese osakaaluga sündmust, siis näitab F1 Score,
et tegu on ebakvaliteetse mudeliga.
Mudeli hindamiseks on veel palju erinevaid valemeid ja nii eeltoodute kui ka teiste kohta saab lähemalt lugeda
siit.
