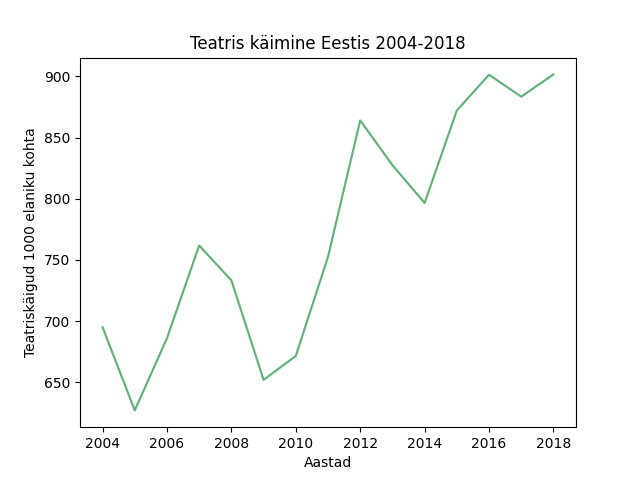
59 Teatrikülastuse näide
Sissejuhatus
Eelmistes peatükkides tutvustati pandase põhilisi andmestruktuure – seeriat (Series) ja andmefreimi (DataFrame). Nüüd tegutseme andmefreimi abil põhjalikumalt tegelike andmetega. Vaatame teatrikülastuse andmeid (allikas: Statistikaamet), kust on valitud andmed kõikide teatrite kohta kokku vahemikus 2004 – 2018. Eelnevalt on andmeid töödeldud tabeltöötlusprogrammiga ja kõik komad failis on muudetud punktideks, sest allalaaditud failis on arvudes kasutatud komasid. Samuti on eemaldatud üleliigsed veerud ja lahtrid.

Samuti on failikodeeringuks määratud UTF-8, mida saab valida näiteks siis, kui fail salvestatakse MS Excelis CSV formaadis. Failikodeeringu kasutamine on eriti oluline siis, kui andmetes on erilisi tähti (näiteks ä, õ jne) või sümboleid, mida on vaja õigesti kuvada.
Andmete saamine failist
Loeme andmed veebist (andmed võid ka alla laadida: teater.csv), mille sisu näeb tavalise tekstiredaktoriga (nt Notepad++) avades välja selline:
;2004;2005;2006;2007;2008;2009;2010;2011;2012;2013;2014;2015;2016;2017;2018 Teatrite arv;21;22;26;30;26;28;29;34;41;41;37;49;46;47;58 Lavastused;326;348;406;414;400;401;417;464;487;490;511;550;540;559;582 ..uuslavastused;121;153;170;164;157;153;173;190;203;186;196;216;196;204;211 Etendused;3974;4288;4651;4765;4635;4731;4593;5012;5678;5803;6010;6434;6573;6713;6695 Vaatajad. tuhat;937.5;843.4;922.1;1022.1;983.1;873.8;899.9;1008.3;1143;1090.7;1047.1;1146.6;1186;1164;1192 Teatriskäigud 1000 elaniku kohta;695;627;686;761.8;733.3;652;671.5;752.5;864.1;827.5;796.6;872.2;901.4;883.5;901.7
Loeme andmed.
import pandas as pd # Andmed url = 'http://kodu.ut.ee/~merka123/plotly/teater.csv' csv = pd.read_csv(url, encoding='UTF-8', sep=';')
Parameeteri sep väärtus näitab, milline eraldaja on andmeid sisaldavas failis määratud, antud juhul on tegemist semikooloniga. Sageli kasutatakse CSV failides eraldajana koma, aga andmetes, kus arvudes kasutatakse koma, ei saa seda eraldajana kasutada.
Funktsiooni read_csv kasutamisel on veel mitmeid muid parameetreid, mida võib vaja minna. Nendega saab lähemalt tutvuda siin.
Tutvumine andmetega
Püüame täpsemalt tutvuda meie poolt sisse loetud tabeliga. Sisseloetud tabel on meil nüüd andmefreimina kasutatav. Püüame näiteks teada saada, mitu veergu ja rida on tabelis.
Funktsioon shape annab andmefreimi mõõtmed (ridade ja veergude arvu):
print(csv.shape)
>>> %Run guido.py (6, 16)
Näeme, et tabelis on 6 rida ja 16 veergu. Uurime ka, millised veerud on andmetabelis.
# Veergude pealkirjad print(csv.columns)
>>> %Run guido.py Index(['Unnamed: 0', '2004', '2005', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013', '2014', '2015', '2016', '2017', '2018'], dtype='object')
Näeme, et tabelis on esimene veerg ilma nimeta (Unnamed: 0), mille põhjuseks on see, et esimeses veerus on erinevad kategooriad, millel ei ole veeru pealkirja. Selle parandamiseks võime esimeses veerus olevad andmed muuta reasiltideks. Selleks tuleb lisada read_csv funktsiooni juurde index_col=0, mille tulemusel kasutatakse esimese veeru andmeid reasiltidena.
csv = pd.read_csv(url, encoding='UTF-8', sep=';', index_col=0) # Väljastame terve tabeli, sest see ei ole väga suur. print(csv)
>>> %Run guido.py 2004 2005 ... 2017 2018 Teatrite arv 21.0 22.0 ... 47.0 58.0 Lavastused 326.0 348.0 ... 559.0 582.0 ..uuslavastused 121.0 153.0 ... 204.0 211.0 Etendused 3974.0 4288.0 ... 6713.0 6695.0 Vaatajad. tuhat 937.5 843.4 ... 1164.0 1192.0 Teatriskäigud 1000 elaniku kohta 695.0 627.0 ... 883.5 901.7 [6 rows x 15 columns]
Uurime, kas andmetes on puuduvaid väärtusi. Kasutame selleks funktsiooni isna ja sum.
print(csv.isna().sum())
>>> %Run guido.py 2004 0 2005 0 2006 0 2007 0 2008 0 2009 0 2010 0 2011 0 2012 0 2013 0 2014 0 2015 0 2016 0 2017 0 2018 0 dtype: int64
Näeme, et puuduvaid väärtusi ei ole. Uurime ka, mis tüüpi on andmed veergudes.
print(csv.dtypes)
>>> %Run guido.py 2004 float64 2005 float64 2006 float64 2007 float64 2008 float64 2009 float64 2010 float64 2011 float64 2012 float64 2013 float64 2014 float64 2015 float64 2016 float64 2017 float64 2018 float64 dtype: object
Veergude andmetüüp on sobiv.
Andmete kajastamine graafikul
Andmete põhjal saab graafiku teha mooduli Matplotlib abil. Enne joonise tegemist, peame aga andmed transponeerima ehk vahetama ära read ja veerud. Nimelt on meil mugavam joonist teha, kui reasiltideks on aastad ja veergudeks on erinevate kategooriate andmed (nt teatrite arv). Nii saame automaatselt määrata, et x-telje andmed on aastad ja y-teljel on mõne kategooria andmed.
# Impordime mooduli import matplotlib.pyplot as plt # Transponeerime andmed, muudame veergude pealkirjad indeksiteks ja indeksid veergude pealkirjadeks. transponeeritud_andmed = csv.T
Transponeeritud andmed:
Teatrite arv ... Teatriskäigud 1000 elaniku kohta 2004 21.0 ... 695.0 2005 22.0 ... 627.0 2006 26.0 ... 686.0 2007 30.0 ... 761.8 2008 26.0 ... 733.3 2009 28.0 ... 652.0 2010 29.0 ... 671.5 ...
Loome joonise.
import pandas as pd
import matplotlib.pyplot as plt
# Andmed
url = 'http://kodu.ut.ee/~merka123/plotly/teater.csv'
csv = pd.read_csv(url, encoding='UTF-8', sep=';', index_col=0)
transponeeritud_andmed = csv.T
transponeeritud_andmed['Teatriskäigud 1000 elaniku kohta'].plot.line(xlabel="Aastad",
ylabel="Teatriskäigud 1000 elaniku kohta",
title="Teatris käimine Eestis 2004-2018",
color='#3CB371')
plt.show()